2026 · legal-tech · AI assistant · construction
Celine AI
An experiment: lien-rights chat for suppliers and equipment lessors: information, not advice, even when it knows your account
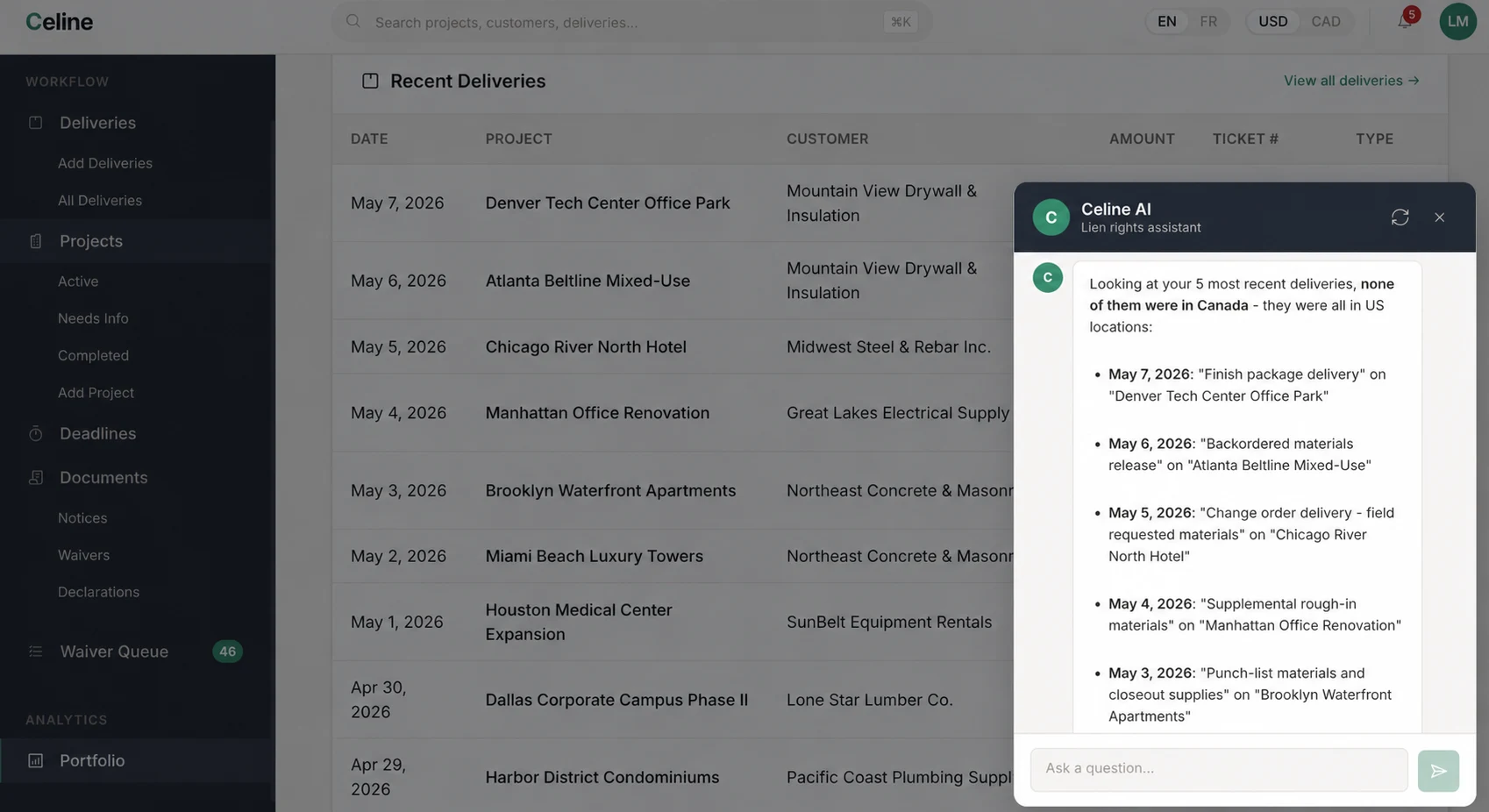
In plain terms: a chat that answers construction payment-rights questions by naming the relevant statute, naming your account state, and stopping short of telling you what to do.
- Status
- wireframe
- Scope
- 26 jurisdictions
- Languages
- EN · FR
- Hard part
- info ≠ advice
why
I spent nearly seven years at Levelset and Procore on lien rights: the way construction suppliers and equipment lessors keep getting paid on jobs that span months and dozens of contractors. Same questions, every week: do I need a preliminary notice in Texas, what’s my exposure on this delivery, did this waiver actually waive anything? The answers always came from two places: the customer’s account state, and a thicket of state-by-state statutory rules.
Celine is the experiment that asked the harder version: can a chat stay on the information side of the line when the model already has your account state? A bot reciting Texas Property Code §53.057 is clearly information. The same bot saying you missed your preliminary notice deadline on the Smith job (same statute, applied to your account) is that still information? The line is one verb wide.
The wireframe scopes to North America because that’s the market reality: US contractors take jobs in Canada, Canadian sub-trades come south. There’s a second test tucked inside the first: I knew US lien law cold, but not Canadian lien law. So the Canadian half ran its own experiment: does statutes-as-context carry a non-expert into a jurisdiction they can’t verify from memory? That’s the more transferable question.
A note on the name. Celine is half homage to Zlien (Levelset’s original name) and half homophone of Céline Dion, who anchors the French-Canadian half of the cross-border scope. Naming the assistant after a person also tilts the discourse: I’d ask Celine and I’d run that by Celine are the natural-language frames that put the user in the right register for what the chat actually is.
what I built
A wireframe of a streaming chat with EN/FR toggle. Account state and statutes both live in the system prompt: no retrieval store, no rules engine, no Postgres backing the wireframe. Context only.
Four starter questions, picked because each tests a different shape:
- What deadlines are coming up?: pull from account state
- Do I need a preliminary notice in Texas?: recall a specific statute
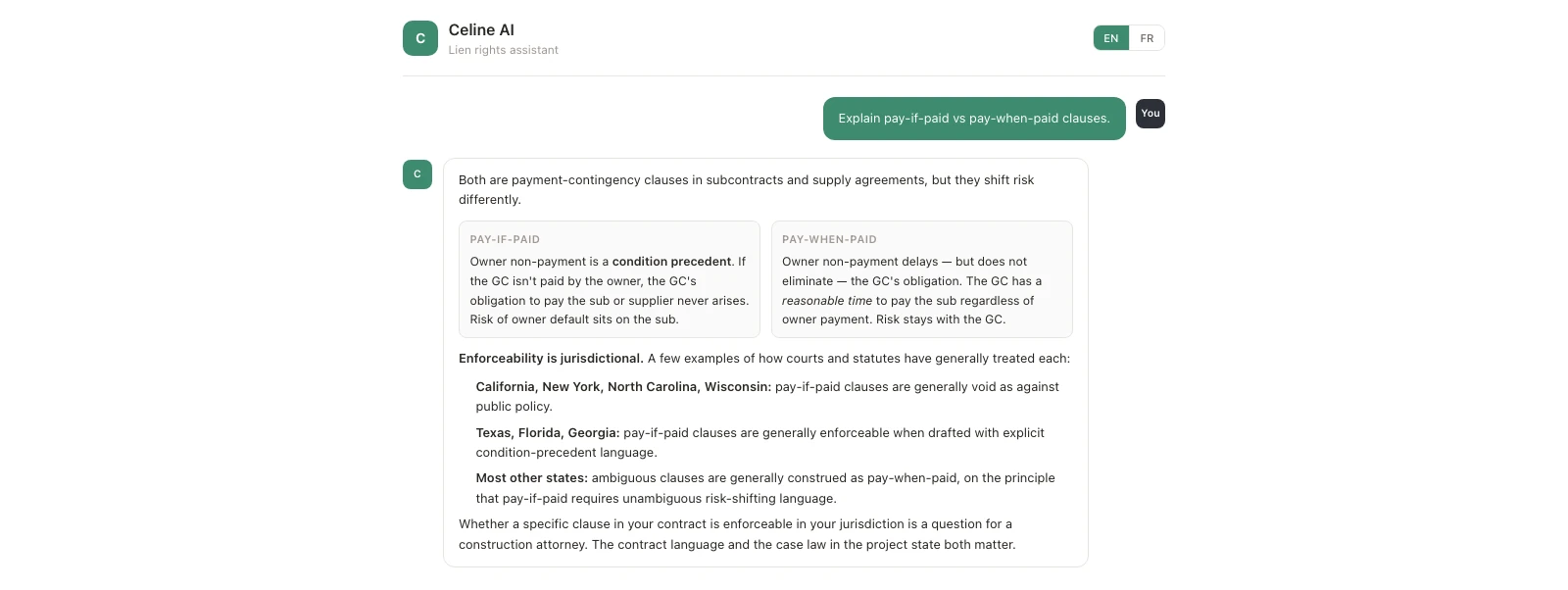
- Explain conditional vs. unconditional waivers.: explain a legal distinction
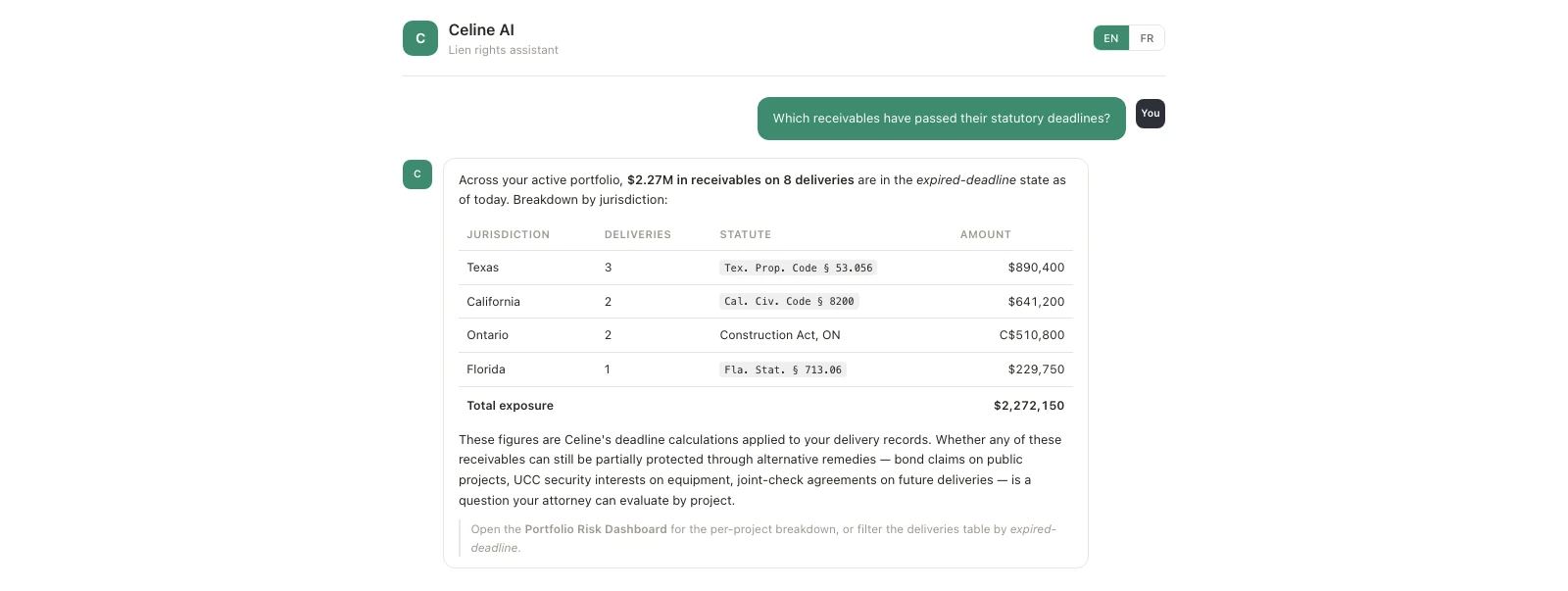
- What are my unprotected receivables?: run a portfolio query
If the chat answered all four from context alone and stayed on the information side on each, the experiment was a yes.
Server-sent streaming so the response feels conversational. EN and FR both ship in the wireframe: Quebec’s civil-law framework (CCDC declarations, provincial holdbacks) is genuinely different from the US AIA-waiver world, so French isn’t a translation layer; it’s a parallel rules surface.
decisions I’d defend
Account-aware first. The interesting test wasn’t can a model recite lien law. That’s been answerable since GPT-3. It was whether the model could hold your account state in one hand and the law for your jurisdictions in the other and answer about this week’s exposure. Whether that holds at production scale is exactly what a wireframe can’t tell you.
Four moves that keep it information, not advice. The line between here’s the rule, here’s your account and here’s what you should do is one verb wide. Four constraints in the system prompt held it:
- Show the rule and the account state separately. The model says Texas requires preliminary notice within 15 days for direct contractors, and your account shows the Smith job delivery on day 20; two facts side by side. The user draws the conclusion.
- Refuse “should I” with “what the rule says + what your account shows.” A user asks should I send a notice on the Brown job? The answer names the statute, names the account state, names the gap. The advice version is yes/no, and the wireframe never gives the second.
- Cite the statute inline on every account-aware answer. No naked claim about your account stands alone. The line reads as the rule, applied, not Celine’s opinion.
- Descriptive, not prescriptive. No you’ll want to, no I’d recommend, no the safe move is. Those are the seam where information becomes advice. The system prompt forbids them by name.
North American first, Spanish flagged. Scoped to 22 US states + 4 Canadian provinces (Alberta, BC, Ontario, Quebec), in EN and FR. The Canadian inclusion was a deliberate test of whether statutes-as-context could carry me into a jurisdiction I couldn’t verify from memory. Spanish is the real missing piece: a production version would have to ship ES on the same first-class footing.

Four welcome questions, very on purpose. Cold-start chat surfaces fail when users don’t know what to ask. The four suggestions are deliberately the four shapes Celine handles best: temporal, jurisdictional, conceptual, portfolio. A fifth would have read as a menu, not an invitation. One seam I’d reword: unprotected receivables in Q4 is the chat doing the user’s labeling. A cautious version says which receivables have passed their statutory deadlines instead.
the prompt as discourse
The four constraints look like policy rules; they’re actually speech-act rules, in the sense J. L. Austin meant: information describes a state of affairs, advice commits the speaker to a position. Cross the line and the chatbot has done something, not reported something.
Three techniques in the system prompt do most of the work:
- Modality shift. Replace you should, you’ll want to, the safe move is with the options that generally exist include, the general statutory deadline is. Same proposition, different speech act.
- Parataxis. When the model has both account state and statute, the rule is to set the two clauses side by side without a connective. Texas requires preliminary notice within fifteen days. Your account shows delivery on day twenty. No therefore, no so. The reader does the inferring.
- Inline evidentiality. Every account-aware answer carries a statutory tag (under California Civil Code § 8412), so the speaker of any claim is the named source, never Celine. The model talks about the law without taking responsibility for it.
The clearest version of all three at once is a worked teaching pair in the system prompt, same facts, different discourse:
WRONG: California’s deadline is 90 days from last furnishing, so you have 5 days left.
RIGHT: Under California Civil Code § 8412, the general deadline to record a mechanics lien is 90 days after completion of the work of improvement. If a notice of completion has been recorded, the deadline may be shortened to 30 days for claimants other than direct contractors (§ 8414). The calculation depends on what constitutes “completion” and whether a notice of completion was recorded. Given potential time sensitivity, contact a California construction attorney immediately.
The wrong version is short, second-person, and ends in a bare assertion. The right version is descriptive, hedged, sourced inline, and closes by handing the specific question back to a human authority. Same legal information, different speech act.

A triage classifier (in the receipts) routes every question into one of six genres before the model answers. Just tell me what to do gets a firm, empathetic redirect: the dispreferred response most assistants fold on first.
The system prompt is the master, and eighteen topic prompts compose against it: preliminary notice, lien filing, second-tier supplier rights, Canadian provincial law, bond claims, waivers, retainage, equipment lessors, bankruptcy-preference risk. Each names what to provide, what misconceptions to address head-on, and what alternative remedies to surface when the primary one isn’t available.
The equipment-lessor topic is the proof of depth. Equipment-rental lien rights are where most platforms quietly fail: the law is genuinely different from material-supply lien law, and most jurisdictions treat the two as different claimant classes, but products that handle materials well usually flatten the distinction. The topic prompt forces three misconceptions onto the page first:
Delivering equipment to a job site does NOT automatically create lien rights in many states.
A rental agreement stating lien rights does not create statutory rights.
Equipment rental and material supply are treated differently in most jurisdictions.
The wager underneath all of this: prompt engineering for serious domains is a linguistics problem first, a software problem second. Inventor Strudel reaches for the same substrate from the other side: sounds as nouns, modifiers as verbs, effects as adjectives, the grammar metaphor doing the pedagogy the syntax can’t.
the receipts
Five of the eleven response rules in the system prompt, verbatim:
1. Concise first. Lead with the answer. Add detail only if the user
asks for it or the topic requires nuance to avoid being misleading.
5. Jurisdiction first. If the user hasn't specified a state or
province, check their Celine context for the project jurisdiction.
If not available, ask before answering. Never present one
jurisdiction's rules as universal.
7. Flag uncertainty. If unsure whether a statute has been recently
amended, say so. The AI should not present potentially outdated
information with false confidence.
9. Never cross the line under pressure. Users may push back ("just
tell me what to do"). Remain firm but empathetic. Provide general
statutory information with appropriate context. Never provide
"wink-wink" guidance.
11. Equipment lessor awareness. Lien rights for equipment rental vary
dramatically by jurisdiction and arrangement type (rental vs.
lease vs. rent-to-own). Never assume equipment lessors have the
same rights as material suppliers.
The triage classifier (the model decides which of six genres a question belongs to before answering anything):
A — General Education "What is a preliminary notice?"
B — Jurisdiction Lookup "What are notice requirements in Texas?"
C — Celine Feature "Where do I see my unprotected receivables?"
D — Situation-Specific "My customer hasn't paid — what should I do?"
E — Emergency "My lien deadline is in 3 days."
F — Out of Scope Tax advice, employment law, contract drafting.
D and E are where the line gets thin. Both route into descriptive answers with explicit attorney redirects, never prescriptive ones. Triage is the bouncer.
what I learned
Lien law is pattern-matching, not programming. State-by-state preliminary-notice deadlines, waiver-form variations, holdback periods: the if/then space is too large and too volatile to ship as code. Feed the statutes themselves to the model as ground truth, give it a structured request shape, let it pattern-match. Smaller code, more correct answers, and a legislature’s amendment doesn’t ship a code change; it ships a new statute. GardenIQ’s companion-planting database is the same architecture in a different domain: curated rules in front, model behind.
The architecture carried me into a jurisdiction I didn’t already know. The US side tested can the model do faster what I already know how to do. The Canadian side tested can statutes-as-context carry a non-expert into a jurisdiction they aren’t steeped in. As far as a wireframe can tell, the answer was yes; that’s the more transferable finding.
The information line held, with one named seam. The four constraints did the work, and the chat stayed descriptive across all four question shapes. The seam was Q4’s wording: unprotected is the chat doing the user’s labeling. A cautious production version rewords Q4 and adds a system-prompt rule against the model adopting any judgment-flavored adjective the user hasn’t introduced first.
UX quality in legal-tech is what didn’t happen, not what got clicked. The four constraints aren’t a stylebook; they’re the metric: every refused should I, every cited statute, every yes the chat didn’t say is a prevented error. The product’s quality is legible only in what isn’t there.
what would prove it
The wireframe answered one question (can context-only stay on the information side of the line?). What a shipped Celine would have to prove next:
- The four constraints generalize past four question shapes. The wireframe tested temporal, jurisdictional, conceptual, and portfolio. Production faces the long tail: the GC’s lawyer told me waivers are unenforceable in Florida, is that true; we paid the wrong tier, can we claw back; the customer says they’ll sue if we don’t lien. The proof is whether the four constraints handle the long tail without each new question shape needing a new prompt rule. Track the rate at which prompt rules get added per hundred unique question shapes; the curve flattening is the proof.
- The Canadian half ports the way the US half does. The wireframe covered four provinces I learned for the experiment. The real test is whether statutes-as-context carries a non-expert into Manitoba or Newfoundland the way it carried me into Ontario and Quebec. If the architecture works on the provinces I haven’t read into, the architecture is the win. If it falters there, the wireframe’s success was specific to jurisdictions whose case law I’d already absorbed.
- The information posture survives equipment-lessor pressure. Equipment-rental lien law is the seam where most lien-rights platforms quietly break: they flatten the difference between rental and material supply. If Celine handles we delivered tools for thirty days but the rental was over six months without sliding into yes, you have lien rights (the easy lie material-supply tools fall into), the topic-prompt depth was real. If users on equipment-lessor accounts churn because the chat keeps redirecting to contact a lawyer, the depth was the wrong kind.
Two risks a shipped Celine would have to keep budgeting for:
- Statutes drift faster than the system prompt does. Cramming statutes into the prompt worked for a 26-jurisdiction wireframe; production needs a versioned retrieval store with a legal-review cadence, change logs, and a way to flag answers given before an amendment took effect. Without that loop, the chat’s confidence becomes a liability the moment the law changes underneath it.
- The information/advice line has no automatic detection. Triage redirects just tell me what to do, but the subtle failures (a hedged opinion shaped like information, a generally, claimants in this position would) don’t fire the redirect. The proof of catch is human discourse audit on a sample of real conversations: randomly sampled, scored against the line, posted alongside reliability metrics. Otherwise the line drifts and nobody notices.
the recipe
The wireframe runs on Next.js 16 + Fastify, no low-code scaffold. PostgreSQL through Kysely, Redis + BullMQ for queues, Anthropic SDK direct to the chat surface. The four constraints from decisions are coded straight into the system prompt, where the line between information and advice actually lives.
The sample data is what makes the wireframe legible. Eight customer accounts, fifteen active projects, forty-six deliveries, 22 US states + 4 Canadian provinces seeded as jurisdictional rules. The customers aren’t Acme Corp; they’re region-coded supplier names with realistic credit profiles, contacts, tier positions, and trade tags.
The tip worth taking home: when a tool needs realistic sample data but can’t have real customers yet, ask Claude. Faster than fixtures, better than Lorem Ipsum. The prompt shape that works isn’t give me 8 sample customers; it’s a three-step description:
- Describe the space. Construction supplier and equipment-lessor businesses, mid-market, Net-30 to Net-60 terms, credit limits $200K–$2M, tier-1 through tier-3 supply-chain positions.
- List the details you need. Account-number conventions, contact name + email + phone (555 prefix), region-suggesting business names, industry-specific tags, a realistic credit-limit distribution, a couple of customers in dispute or on hold.
- Ask for the records. Eight customers across the US plus two in Canada, a mix of plumbing, steel, electrical, HVAC, with one long-tail problem account.
The work is the description, not the request. A weak prompt returns Acme Construction Co. with a flat credit limit and no shape; a described prompt returns a regional supplier name with a credit limit matching the segment, trade tags matching the work, and a contact whose area code matches the region. Pattern-matched to the space, not generated from a thesaurus. The same pattern runs through Pocketbook’s caption pipeline: describe the bag, describe the specificity needed, let the model do the noticing.
method extracted: Guarded AI Assistant Design
Celine is the project. Guarded AI Assistant Design is the reusable pattern. The assistant should inform without advising. Separate the rule, the user/account state, and application factors. Control verbs and conclusions. Information, not advice. No therefore, no so. The reader does the inferring.
Related methods: Prompt as Discourse · Rules before AI.
what’s next
The experiment ran, and it lives in a wireframe. What it would take to become a real product:
- Statutes pulled from a versioned retrieval store, not crammed into a system prompt
- Account state from real Postgres, not fixtures
- An evaluation harness that catches regressions when a state legislature amends
- Spanish on the same first-class footing as EN and FR
None of that was the experiment’s job. The experiment was answering can context-only stay on the information side of the line, and the answer was good enough to bookmark, not good enough to ship.
See also
All projects- Periodic Table of Taylor Swift Same lab-notebook habit: show the working, never overwrite a reversal. The Periodic Table keeps every dropped column in plain view; Celine lays the rule and your account side by side and lets the reader do the inferring.
- Pocketbook Same division of labor: AI drafts, the human edits before it ships. Pocketbook hand-edits captions; Celine refuses to issue advice the model could plausibly write.
- Discover Sacramento Same edge-function spine, different jurisdiction. Celine brokers lien statutes and account state; Sacramento brokers map tiles and ElevenLabs audio. Both refuse to leak a key to the client.
Working on something similar?
I take a small handful of consulting briefs a year and am always up for trading notes with anyone shipping in this space — send a note.
Or: values behind the work · obsessions that shape it · other projects.
